IMDB Movie Recommendation System

About the Project
In this I will be building a Movie Recommender System based on IMDB Dataset.Recommender System are quite useful and popular these.whether it be an E-commerce company or food Delivery Service,Everyone requires a recommender system.It helps them to understand
their customers while it also provides a smooth user flow for the users to go through the website.Throughout this Notebook ,I will be discussing various Approaches to build a recommender system ,common algorithms to build a recommender system
and also a small demo of how recommendation will be shown to the user.
Exploring and Visualization
The Dataset we are using for this project can be found here.The Dataset comprises of 2 csv files.Lets import our libraries and see what data we have in the csv file
# linear algebra import numpy as np
# data processing, CSV file I/O (e.g. pd.read_csv)
import pandas as pd
# for visualizations and plotting graphs
import matplotlib.pyplot as plt
import seaborn as sns
#setting the style of grids
sns.set_style('whitegrid') There are two files tmdb_5000_movies.csv and tmdb_5000_credits.csv.Lets go through them one by one
#Load the First csv File
data_movies = pd.read_csv('Data/tmdb_5000_movies.csv')
#Load the second csv File
data_credits = pd.read_csv('Data/tmdb_5000_credits.csv')
#Print the first 1 rows of the data_movies
data_movies.head(1) | budget | genres | homepage | id | keywords | original_language | original_title | overview | popularity | production_companies | production_countries | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 237000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://www.avatarmovie.com/ | 19995 | [{"id": 1463, "name": "culture clash"}, {"id":... | en | Avatar | In the 22nd century, a paraplegic Marine is di... | 150.437577 | [{"name": "Ingenious Film Partners", "id": 289... | [{"iso_3166_1": "US", "name": "United States o... | 2009-12-10 | 2787965087 | 162.0 | [{"iso_639_1": "en", "name": "English"}, {"iso... | Released | Enter the World of Pandora. | Avatar | 7.2 | 11800 |
Now lets understand what each feature is
data_movies.columns Some feature columns are explained as below:RangeIndex: 4803 entries, 0 to 4802 Data columns (total 20 columns): budget 4803 non-null int64 genres 4803 non-null object homepage 1712 non-null object id 4803 non-null int64 keywords 4803 non-null object original_language 4803 non-null object original_title 4803 non-null object overview 4800 non-null object popularity 4803 non-null float64 production_companies 4803 non-null object production_countries 4803 non-null object release_date 4802 non-null object revenue 4803 non-null int64 runtime 4801 non-null float64 spoken_languages 4803 non-null object status 4803 non-null object tagline 3959 non-null object title 4803 non-null object vote_average 4803 non-null float64 vote_count 4803 non-null int64 dtypes: float64(3), int64(4), object(13) memory usage: 750.5+ KB None
genre: states the genre of the film along with the genre id i.e comedy,drama
budget: budget of the movie
homepage: url of the movie website
keywords: indicates the plot of keywords which define the movies
genre: states the genre of the film along with the genre id i.e comedy,drama
original_languages: original language in which movie was produced
popularity : Popularity of movie
vote_avg : Average votes given to that movie
vote_count : total no of votes given to that movie
We will be exploring many of the columns later in the notebook and also understand what they
Exploratory Data Analysis
In this section we will be analyzing the feature columns , their distribution over the dataset and what insights do we get from the plots or charts1.1 Original language
Lets find out what is most popular language in which films are produced
fig = plt.figure(figsize=(8,8))
sns.countplot(y=data_movies['original_language'],data=data_movies) 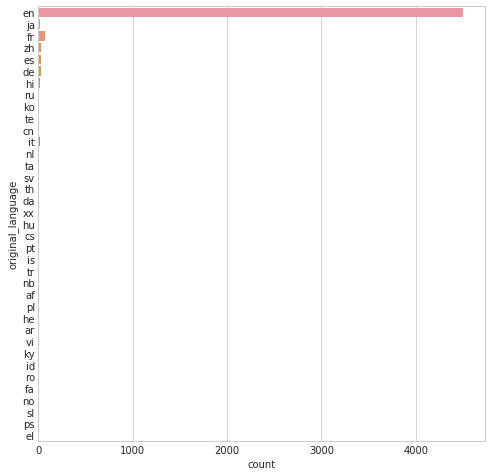
1.2 Popular Genres
In this section we will analyze which genre is most common among movies. i.e on which genre most of the movies are based.
import ast genres_movies = dict()
for movies in data_movies['genres']:
movie = ast.literal_eval(movies)
for genre in movie:
if(genre['name'] not in genres_movies.keys()):
genres_movies[genre['name']] = 1
else:
genres_movies[genre['name']]= genres_movies[genre['name']]+1 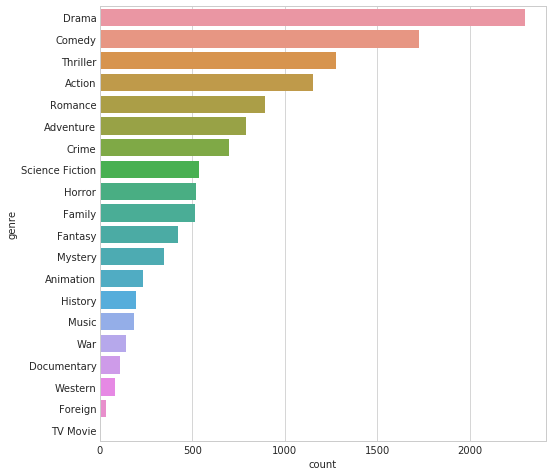
Recommender Systems
Recommendation Systems are of mainly 3 different types.Each one offers a different level of personalization.Most recommender systems take either of two basic approaches: collaborative filtering or content-based filtering. Other approaches (such as hybrid approaches) also exist.
-
Collaborative Filtering
In Collaborative Filtering,recommendations are based on prior user experience.Collaborative filtering uses group knowledge to form a recommendation based on like users.
-
Content Based Filtering
Content-based filtering constructs a recommendation on the basis of a user's behavior.This definitely requires user browser history ,what kinds of content and blogs he is reading and recommends based on the History.Suppose we were to build a blog recommendation and if a particular user reads blogs about linux , the system would recommend blogs like operating system , ubuntu and other unix based operating.This is what user may like.
-
Hybrid Approach
In hybrid based Approach , that combines both the Collaborative and Content based approach is more complex as compared to both above.The Content based filtering could be used if the user data is not mature enough to be compared with other user data and give a cold start to the system but slight shift towards Collaborative approach when the user data grows enough.
Weighted Voting Approach
Weighted Voting Approach is simple common approach which doesn't takes any user activity into account. It simply uses a predefined ranking formula to rate movie based on their votes,views etc.
If we peek into our data,we have a lot of features like
Vote Average,
Vote Count,Popularity
Building our Simple Engine
The rating formula for IMDB is :
weighted rating (WR) = (v ÷ (v+m)) × R + (m ÷ (v+m)) × CR : average for the movie (mean) = (Rating) v:number of votes for the movie = (votes) m: minimum votes required to be listed in the Top 250 (currently 25000) C :the mean vote across the whole report (currently 7.0)
Now lets peek again into our movies data
data_movies.head(1) | budget | genres | homepage | id | keywords | original_language | original_title | overview | popularity | production_companies | production_countries | release_date | revenue | runtime | spoken_languages | status | tagline | title | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 237000000 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | http://www.avatarmovie.com/ | 19995 | [{"id": 1463, "name": "culture clash"}, {"id":... | en | Avatar | In the 22nd century, a paraplegic Marine is di... | 150.437577 | [{"name": "Ingenious Film Partners", "id": 289... | [{"iso_3166_1": "US", "name": "United States o... | 2009-12-10 | 2787965087 | 162.0 | [{"iso_639_1": "en", "name": "English"}, {"iso... | Released | Enter the World of Pandora. | Avatar | 7.2 | 11800 |
Lets calculate the mean vote,average vote
vote_counts = data_movies[data_movies['vote_count'].notnull()]['vote_count'].astype('int')
# we will be using minimum votes as 95% percentile of the maximum votes received
#calculating the average votes
vote_averages = data_movies[data_movies['vote_average'].notnull()]['vote_average'].astype('int')
# setting minimum vote requirements to be 85 percentile of the votes of the movies
minimum_votes = votes_count.quantile(0.85)
print 'minimum_votes :',minimum_votes 1300
Now we have calculated the minimum vote requirements for the movies to be listed in our chart.Let's extract all the movies from our dataframe which qualifies above criteria
qualified = data_movies[(data_movies['vote_count'] >= m) & (data_movies['vote_count'].notnull()) & (data_movies['vote_average'].notnull())][['title', 'year', 'vote_count', 'vote_average', 'popularity', 'genres']]
qualified['vote_count'] = qualified['vote_count'].astype('int')
qualified['vote_average'] = qualified['vote_average'].astype('int')
qualified.shape (721, 6)
According to our criteria for listing movies we have 721 movies ready to be recommended to our user
Now we will use the standard IMDB rating formula to calculate the weighted rating for all qualified movies.
def weighted_rating(x):
v = x['vote_count']
R = x['vote_average']
return (v/(v+m) * R) + (m/(m+v) * C)we have defined our weighted_rating function which calculates weighted rating for movies.
qualified['wr'] = qualified.apply(weighted_rating, axis=1)
qualified = qualified.sort_values('wr', ascending=False).head(100) | index | title | year | vote_count | vote_average | popularity | genres | wr | |
|---|---|---|---|---|---|---|---|---|
| 90 | 96 | Inception | 2010 | 13752 | 8 | 167.583710 | [{"id": 28, "name": "Action"}, {"id": 53, "nam... | 7.740771 |
| 63 | 65 | The Dark Knight | 2008 | 12002 | 8 | 187.322927 | [{"id": 18, "name": "Drama"}, {"id": 28, "name... | 7.706669 |
| 89 | 95 | Interstellar | 2014 | 10867 | 8 | 724.247784 | [{"id": 12, "name": "Adventure"}, {"id": 18, "... | 7.679307 |
| 355 | 662 | Fight Club | 1999 | 9413 | 8 | 146.757391 | [{"id": 18, "name": "Drama"}] | 7.635784 |
| 209 | 262 | The Lord of the Rings: The Fellowship of the Ring | 2001 | 8705 | 8 | 138.049577 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 7.610012 |
| 671 | 3232 | Pulp Fiction | 1994 | 8428 | 8 | 121.463076 | [{"id": 53, "name": "Thriller"}, {"id": 80, "n... | 7.598908 |
| 558 | 1881 | The Shawshank Redemption | 1994 | 8205 | 8 | 136.747729 | [{"id": 18, "name": "Drama"}, {"id": 80, "name... | 7.589499 |
| 241 | 329 | The Lord of the Rings: The Return of the King | 2003 | 8064 | 8 | 123.630332 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 7.583318 |
| 388 | 809 | Forrest Gump | 1994 | 7927 | 8 | 138.133331 | [{"id": 35, "name": "Comedy"}, {"id": 18, "nam... | 7.577132 |
| 242 | 330 | The Lord of the Rings: The Two Towers | 2002 | 7487 | 8 | 106.914973 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 7.555959 |
| 659 | 2912 | Star Wars | 1977 | 6624 | 8 | 126.393695 | [{"id": 12, "name": "Adventure"}, {"id": 28, "... | 7.507603 |
| 72 | 77 | Inside Out | 2015 | 6560 | 8 | 128.655964 | [{"id": 18, "name": "Drama"}, {"id": 35, "name... | 7.503594 |
| 593 | 2285 | Back to the Future | 1985 | 6079 | 8 | 76.603233 | [{"id": 12, "name": "Adventure"}, {"id": 35, "... | 7.471239 |
| 679 | 3337 | The Godfather | 1972 | 5893 | 8 | 143.659698 | [{"id": 18, "name": "Drama"}, {"id": 80, "name... | 7.457567 |
| 561 | 1990 | The Empire Strikes Back | 1980 | 5879 | 8 | 78.517830 | [{"id": 12, "name": "Adventure"}, {"id": 28, "... | 7.456509 |
| 510 | 1553 | Se7en | 1995 | 5765 | 8 | 79.579532 | [{"id": 80, "name": "Crime"}, {"id": 9648, "na... | 7.447740 |
| 621 | 2522 | The Imitation Game | 2014 | 5723 | 8 | 145.364591 | [{"id": 36, "name": "History"}, {"id": 18, "na... | 7.444438 |
| 302 | 494 | The Lion King | 1994 | 5376 | 8 | 90.457886 | [{"id": 10751, "name": "Family"}, {"id": 16, "... | 7.415565 |
| 506 | 1532 | The Grand Budapest Hotel | 2014 | 4519 | 8 | 74.417456 | [{"id": 35, "name": "Comedy"}, {"id": 18, "nam... | 7.329502 |
| 575 | 2091 | The Silence of the Lambs | 1991 | 4443 | 8 | 18.174804 | [{"id": 80, "name": "Crime"}, {"id": 18, "name... | 7.320630 |
| 466 | 1196 | The Prestige | 2006 | 4391 | 8 | 74.440708 | [{"id": 18, "name": "Drama"}, {"id": 9648, "na... | 7.314423 |
| 545 | 1818 | Schindler's List | 1993 | 4329 | 8 | 104.469351 | [{"id": 18, "name": "Drama"}, {"id": 36, "name... | 7.306872 |
| 699 | 3865 | Whiplash | 2014 | 4254 | 8 | 192.528841 | [{"id": 18, "name": "Drama"}] | 7.297514 |
| 362 | 690 | The Green Mile | 1999 | 4048 | 8 | 103.698022 | [{"id": 14, "name": "Fantasy"}, {"id": 18, "na... | 7.270458 |
| 688 | 3573 | Memento | 2000 | 4028 | 8 | 60.715151 | [{"id": 9648, "name": "Mystery"}, {"id": 53, "... | 7.267720 |
| 594 | 2294 | Spirited Away | 2001 | 3840 | 8 | 118.968562 | [{"id": 14, "name": "Fantasy"}, {"id": 12, "na... | 7.240940 |
| 592 | 2284 | The Shining | 1980 | 3757 | 8 | 78.699993 | [{"id": 27, "name": "Horror"}, {"id": 53, "nam... | 7.228483 |
| 712 | 4300 | Reservoir Dogs | 1992 | 3697 | 8 | 66.925866 | [{"id": 80, "name": "Crime"}, {"id": 53, "name... | 7.219221 |
| 638 | 2731 | The Godfather: Part II | 1974 | 3338 | 8 | 105.792936 | [{"id": 18, "name": "Drama"}, {"id": 80, "name... | 7.158794 |
| 684 | 3454 | The Usual Suspects | 1995 | 3254 | 8 | 64.025031 | [{"id": 18, "name": "Drama"}, {"id": 80, "name... | 7.143281 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 57 | 57 | WALL·E | 2008 | 6296 | 7 | 66.390712 | [{"id": 16, "name": "Animation"}, {"id": 10751... | 6.657562 |
| 483 | 1356 | The Hangover | 2009 | 6173 | 7 | 82.211660 | [{"id": 35, "name": "Comedy"}] | 6.651926 |
| 82 | 88 | Big Hero 6 | 2014 | 6135 | 7 | 203.734590 | [{"id": 12, "name": "Adventure"}, {"id": 10751... | 6.650147 |
| 240 | 328 | Finding Nemo | 2003 | 6122 | 7 | 85.688789 | [{"id": 16, "name": "Animation"}, {"id": 10751... | 6.649535 |
| 46 | 46 | X-Men: Days of Future Past | 2014 | 6032 | 7 | 118.078691 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.645233 |
| 190 | 231 | Monsters, Inc. | 2001 | 5996 | 7 | 106.815545 | [{"id": 16, "name": "Animation"}, {"id": 35, "... | 6.643483 |
| 152 | 182 | Ant-Man | 2015 | 5880 | 7 | 120.093610 | [{"id": 878, "name": "Science Fiction"}, {"id"... | 6.637723 |
| 160 | 191 | Harry Potter and the Prisoner of Azkaban | 2004 | 5877 | 7 | 79.679601 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 6.637572 |
| 363 | 693 | Gone Girl | 2014 | 5862 | 7 | 143.041543 | [{"id": 9648, "name": "Mystery"}, {"id": 53, "... | 6.636813 |
| 216 | 276 | Harry Potter and the Chamber of Secrets | 2002 | 5815 | 7 | 132.397737 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 6.634414 |
| 179 | 216 | Life of Pi | 2012 | 5797 | 7 | 51.328145 | [{"id": 12, "name": "Adventure"}, {"id": 18, "... | 6.633487 |
| 260 | 356 | Sherlock Holmes | 2009 | 5766 | 7 | 57.834787 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.631879 |
| 79 | 85 | Captain America: The Winter Soldier | 2014 | 5764 | 7 | 72.225265 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.631775 |
| 196 | 239 | Gravity | 2013 | 5751 | 7 | 110.153618 | [{"id": 878, "name": "Science Fiction"}, {"id"... | 6.631096 |
| 105 | 114 | Harry Potter and the Goblet of Fire | 2005 | 5608 | 7 | 101.250416 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 6.623460 |
| 104 | 113 | Harry Potter and the Order of the Phoenix | 2007 | 5494 | 7 | 78.144395 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 6.617143 |
| 315 | 519 | Now You See Me | 2013 | 5487 | 7 | 71.124686 | [{"id": 53, "name": "Thriller"}, {"id": 80, "n... | 6.616748 |
| 214 | 274 | Gladiator | 2000 | 5439 | 7 | 95.301296 | [{"id": 28, "name": "Action"}, {"id": 18, "nam... | 6.614018 |
| 499 | 1465 | The Maze Runner | 2014 | 5371 | 7 | 131.815575 | [{"id": 28, "name": "Action"}, {"id": 9648, "n... | 6.610084 |
| 115 | 124 | Frozen | 2013 | 5295 | 7 | 165.125366 | [{"id": 16, "name": "Animation"}, {"id": 12, "... | 6.605592 |
| 8 | 8 | Harry Potter and the Half-Blood Prince | 2009 | 5293 | 7 | 98.885637 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 6.605472 |
| 508 | 1541 | Toy Story | 1995 | 5269 | 7 | 73.640445 | [{"id": 16, "name": "Animation"}, {"id": 35, "... | 6.604031 |
| 12 | 12 | Pirates of the Caribbean: Dead Man's Chest | 2006 | 5246 | 7 | 145.847379 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | 6.602639 |
| 94 | 101 | X-Men: First Class | 2011 | 5181 | 7 | 3.195174 | [{"id": 28, "name": "Action"}, {"id": 878, "na... | 6.598655 |
| 248 | 339 | The Incredibles | 2004 | 5152 | 7 | 77.817571 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.596851 |
| 342 | 628 | Saving Private Ryan | 1998 | 5048 | 7 | 76.041867 | [{"id": 18, "name": "Drama"}, {"id": 36, "name... | 6.590247 |
| 359 | 687 | 300 | 2006 | 4997 | 7 | 65.197968 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.586929 |
| 395 | 828 | Kill Bill: Vol. 1 | 2003 | 4949 | 7 | 79.754966 | [{"id": 28, "name": "Action"}, {"id": 80, "nam... | 6.583756 |
| 70 | 74 | Edge of Tomorrow | 2014 | 4858 | 7 | 79.456485 | [{"id": 28, "name": "Action"}, {"id": 878, "na... | 6.577606 |
| 357 | 675 | Jurassic Park | 1993 | 4856 | 7 | 40.413191 | [{"id": 12, "name": "Adventure"}, {"id": 878, ... | 6.577468 |
Now we have implemented a basic rating system which gives pretty good recommendations based on various movies metrics.We see that three Christopher Nolan Films, Inception, The Dark Knight and Interstellar occur at the very top of our chart. The chart also indicates a strong bias of IMDB Users towards particular genres and directors.
Now lets build recommendations based on particular movie genres.85% of movie genre ratings will be used to build our movie chart
Genre Based Recommendation
As we have seen above,we calculated the mean_vote and vote percentile for rating and listing movies,we will be using the same strategy to build recommendation
# Its returns movies if movie contains the specified genre
def genre_movies(x,genre):
if genre in x['movie_genres']:
return x Now lets write a function that returns top movies belonging to particular genre
# it returns all movies of particular genre if they qualified movie criteria to be listed
def genre_recommend(genre,percentile):
gen_movie = data_movies.apply(lambda x : ret_mov(x,genre),axis=1)
gen_movie = gen_movie.dropna()
vote_count= gen_movie[gen_movie['vote_count'].notnull()]['vote_count'].astype('int')
vote_averages = gen_movie[gen_movie['vote_average'].notnull()]['vote_average'].astype('int')
c = vote_averages.mean()
m = vote_counts.quantile(percentile)
gen_qualified = gen_movie[(gen_movie['vote_count'] >= m) & (gen_movie['vote_count'].notnull()) & (gen_movie['vote_average'].notnull())][['title', 'year', 'vote_count', 'vote_average', 'popularity', 'genres']]
gen_qualified['vote_count'] = gen_qualified['vote_count'].astype('int')
gen_qualified['vote_average'] = gen_qualified['vote_average'].astype('int')
gen_qualified['wr'] = gen_qualified.apply(lambda x:weighted_rating(x),axis=1)
gen_qualified = gen_qualified.sort_values('wr',ascending=False)
return gen_qualified Now lets check our recommendations.
genre_recommend('Science Fiction',0.85).head(10) | title | year | vote_count | vote_average | popularity | genres | wr | |
|---|---|---|---|---|---|---|---|
| 96 | Inception | 2010 | 13752 | 8 | 167.583710 | [{"id": 28, "name": "Action"}, {"id": 53, "nam... | 7.740771 |
| 95 | Interstellar | 2014 | 10867 | 8 | 724.247784 | [{"id": 12, "name": "Adventure"}, {"id": 18, "... | 7.679307 |
| 2912 | Star Wars | 1977 | 6624 | 8 | 126.393695 | [{"id": 12, "name": "Adventure"}, {"id": 28, "... | 7.507603 |
| 2285 | Back to the Future | 1985 | 6079 | 8 | 76.603233 | [{"id": 12, "name": "Adventure"}, {"id": 35, "... | 7.471239 |
| 1990 | The Empire Strikes Back | 1980 | 5879 | 8 | 78.517830 | [{"id": 12, "name": "Adventure"}, {"id": 28, "... | 7.456509 |
| 0 | Avatar | 2009 | 11800 | 7 | 150.437577 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.801430 |
| 16 | The Avengers | 2012 | 11776 | 7 | 144.448633 | [{"id": 878, "name": "Science Fiction"}, {"id"... | 6.801066 |
| 94 | Guardians of the Galaxy | 2014 | 9742 | 7 | 481.098624 | [{"id": 28, "name": "Action"}, {"id": 878, "na... | 6.764424 |
| 127 | Mad Max: Fury Road | 2015 | 9427 | 7 | 434.278564 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | 6.757506 |
| 634 | The Matrix | 1999 | 8907 | 7 | 104.309993 | [{"id": 28, "name": "Action"}, {"id": 878, "na... | 6.745153 |
Now our movie recommender system recommends movies based on a particular genre.this could serve as one of the strategy for recommending movies.But it provides no personalization for users and recommendations are purely genre based.Let's improve
our system by using content like movies overview,tagline for recommendations
Content Based Filtering
As we have already seen a couple of techniques for building recommendation engines we will be targeting a content based recommendation engine. we will be utilizing the tagline and overview of the to recommend the Movies.Lets
start building our content based recommender system
# create a shallow copy so that we don't alter the original dataframe
content_movies = data_movies.copy(False)
As you can infer we have created a auxiliary dataframe to hold the overview and the tagline.Now lets merge these two columns and join them to create a description column in the content_movies dataframe.
# join overview and tagline content_movies
['description'] = content_movies['tagline'] + content_movies['overview']
#remove missing data
content_movies['description'] = content_movies['description'].fillna('') We have joined the feature columns and remove useless data.Now we will extract features from the description using Tfidf(Term frequency inverse document frequency)
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer(analyzer='word',ngram_range=(1, 2),min_df=0, stop_words='english') tfidf_matrix = tf.fit_transform(content_movies['description']) Now lets see our tfidf matrix shape to analyze what what tfidf matrix really is
tfidf_matrix.shape (4803, 128039)
we have got our Tfidf matrix of shape 4803x128039.the 4803 is total no of movies in our dataframe.128039 is size of feature vector i.e we have got 128039 features for a single movie.Now we have to predict how similar
a movie is to other movies using its feature vector.
Cosine Similarity
Cosine Similarity is a measure of similarity between two non zero vectors.It measures the cosine angle between two non zero vectors. cosine 0represents maximum similarity with value of cosine 1. cosine 0 represents least similarity.
Cosine similarity between two vectors can be mathematically represented as

In our case we have calculated the Tfidf matrix where each row represents a feature vector of a particular movie. Since we need to predict similarity between feature vectors of movies in Tfidf matrix ,we need to find the dot-product of tfidf matrix which will give us a cosine similarity score.This score denotes how similar movies are to each other.
We will be using sklearn's linear_kernel which is faster than dot product and gives us the similarity score
from sklearn.pairwise import linear_kernel
cos_sim = linear_kernel(tfidf_matrix)
cos_sim[0] array([ 1. , 0.00680476, 0. , ..., 0. , 0.00344913, 0. ])
Now lets build recommendation using our calculated similarity scores.Note that now movies will be recommended using the tagline and movie overview.This is a much better approach as compared to our previous approaches as now recommendations will much be user centric.
def improved_recommend(title):
idx = indices[title]
sim_scores = list(enumerate(cos_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:31] movie_indices = [i[0] for i in sim_scores]
return titles.iloc[movie_indices]
improved_recommend('The Shawshank Redemption').head(20) 637 Les Misérables 3785 Prison 609 Escape Plan 2868 Fortress 4727 Penitentiary 434 The Longest Yard 3978 Amnesiac 1187 Bridge of Spies 642 Unbroken 891 Man on the Moon 1779 The 40 Year Old Virgin 791 Goosebumps 1171 Dumb and Dumber To 1166 Get Hard 2570 Ramona and Beezus 1597 Southpaw 42 Toy Story 3 2798 The Boy in the Striped Pyjamas 1860 Kiss of the Dragon 3871 A Christmas Story Name: title, dtype: object
It seems like recommendations have improved from previous approaches.Movies like The Prison and Escape Plan seems to have a similar story plot as The Shawshank Redemption.
Here we come to the End of the Project.We have build a movie recommendation system that recommends movies based on user choice and similarity of movies.
There are several approaches which could further improve the recommendations like using CastCrew Members,Director in the Description so that user will get much better recommendation.
Also hybrid approaches like using popularity as well as description of the movies to predict similarity .I might also try these approaches later.