Movie Reviews Sentiment Analysis Using Machine Learning

About the Project
In this Project we will be building a Sentiment Analyzer that will be used to judge sentiment of movie reviews.
The dataset has been taken from the rotten tomatoes website.We will be dealing will Natural language processing in python and will be sung several modules of python for NLP.This notebook aims at cleaning data as we are dealing with raw reviews.Lets start
Exploration and Analysis
Lets import our libraries
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np we are having only one data file train.tsv . Now tsv(tab seprate values) are another extension of data files just like .xls or .csv. Pandas has a special function read_table which allows us to deal with these files/
lets see what we have in these files
data = pd.read_table('train.tsv')
data.head(5) | PhraseId | SentenceId | Phrase | Sentiment | |
|---|---|---|---|---|
| 0 | 1 | 1 | A series of escapades demonstrating the adage ... | 1 |
| 1 | 2 | 1 | A series of escapades demonstrating the adage ... | 2 |
| 2 | 3 | 1 | A series | 2 |
| 3 | 4 | 1 | A | 2 |
| 4 | 5 | 1 | series | 2 |
The Phrase has all the Sentiments of the reviews.The reviews have been parsed by the stanford parser and split into sentences. Each review has a sentence id and a phrase id.
Now if we observe the sentiments columns we have multiclass labels to sentiments.sentiments have 0,1,2,3,4 numeric classes.Tne dataset source stated that what each numeric label meant so
0 : Negative
1 : Somewhat Negative
2 : Neutral
3 : Positive
4 : Somewhat Postive
For visualization purpose lets convert the numeric columns to categorical.Lets write a method to convert each row of pandas dataframe to numerical
def num_sen(x):
if(x == 0):
return "negative"
if(x == 1):
return "somewhat negative"
if(x == 2):
return "neutral"
if(x == 3):
return "positive"
if(x==4):
return "somewhat positive" Now we will analyze the distribution of various sentiments of dataset
data['Sentiment'] = data['Sentiment'].map(num_sen)
sns.countplot(y=data.Sentiment) 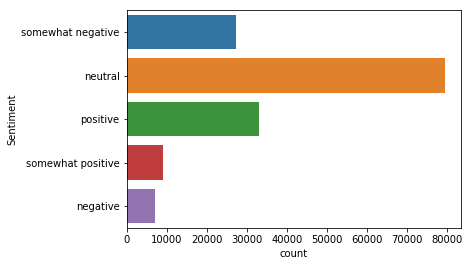
Looks like we have a lot of samples belonging to neutral class :-).People try to be Diplomatic in film reviews
Positive Sentiments Analysis
In this Section we will focus only on the Positive Sentiments from the dataset.We will breakdown sentiments into words,Clean the data and visualize.
Lets extract the positive sentiments out of the Sentiments column
df_sentiments = data[data['Sentiment'] == "positive"] Now we will split each sentence into tokens of words.
positive = df_sentiments['Phrase'].apply(lambda x : x.split(' ')) After this we will count the words which occur in positive sentiments and their counts.this will help us understand what positive sentence mainly comprises of and what do we actually have in them.
positive_dict = dict()
for words in positive:
for word in words:
if word not in positive_dict.keys():
positive_dict[word] = 1
else:
positive_dict[word] = positive_dict[word]+1 Framing the results into dataset for visualization.
positive_counts = pd.DataFrame([[x,positive_dict[x]] for x in positive_dict],columns=['word','count']) Lets do a barplot
fig = plt.figure(figsize=(12,18
sns.barplot(y = positive_counts['word'][:100],x=positive_counts['count'][:100]) 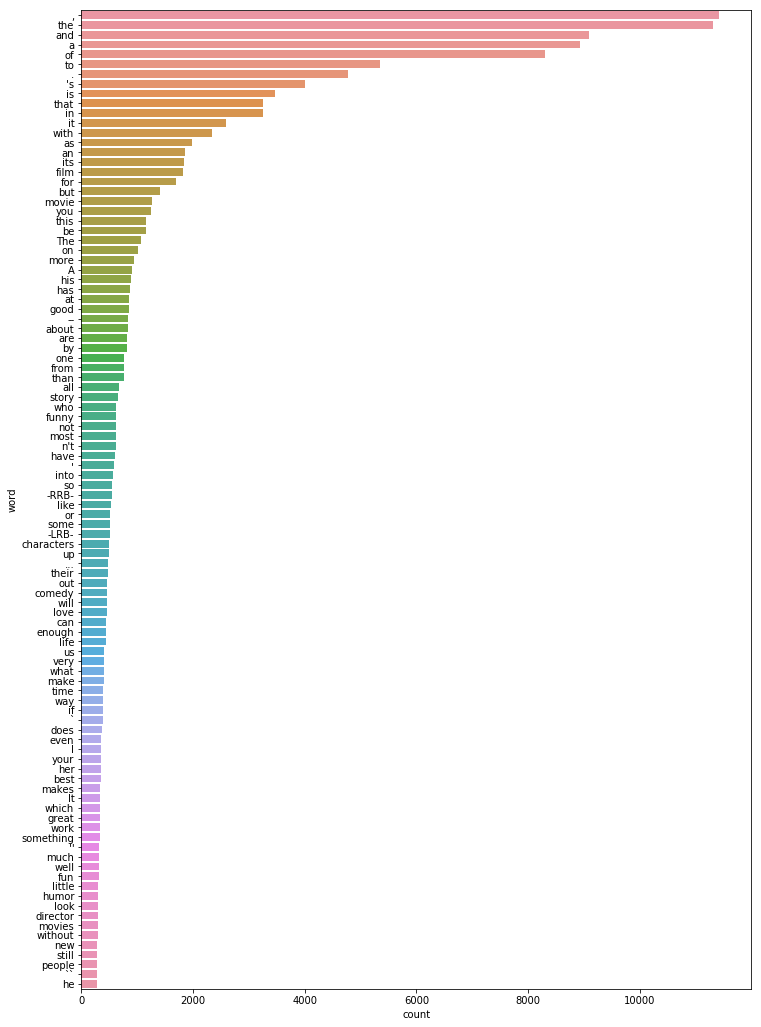
It seems like the most common word or element or token is , followed by the and other
articles,pos(parts of speech).It seems pretty obvious because these comprises of most of what we speak in daily life. The and and are the most common words in English Sentences.
But regarding building predictive model for sentiments analysis these wont play a special role as they would be common to all sentences.
Cleaning the Positive reviews
Now its time to gear up and clean our reviews. we have seen in above visualization that these are prominent in our reviews and don't play much important role.we would be cleaning reviews using the python Natural Language Processing library
NLTK
import nltk from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer from nltk.stem.wordnet import WordNetLemmatizer set(stopwords.words('english')) nltk.download('wordnet') we have imported stopwords Stemmer Lemmatizer and downloaded the wordnet for Lemmatizer.we will see what each of these are and how they will clean our reviews
-
Stop words Punctuations and special characters
Stop words are words which are very repetitive and useless.These words means nothing, unless of course we're searching for someone who is maybe lacking confidence, is confused, or hasn't practiced much speaking. We all do it, you can hear me saying "umm" or "uhh"
- Stemming
Stemming is the process of reducing a word into its stem, i.e. its root form.root form of eating is eat,sleeping is sleep.converting words to roots reduces ambiguity in sentences
- Lemmatizing
Lemmatization is somewhat similar to stemming but it maps several different words to a common root
for eg: go,going,went are mapped to go
Now we will write a function that does this for us . Since Both Stemming and Lemmatization reduces words into their root forms , any one can be used.I will be using Lemmatization in this Notebook.we will also use python inbuilt regular expression
library re for removing symbols and special characters and Numbers.
import re
# lets define a function that does this
def clean_reviews(review):
# removing the punctuation and special symbols
review = re.sub('[^A-Za-z]+',' ',review)
# converting words to lowercase
review = review.lower()
# converting sentences to list of words
review = review.split(' ')
# removing the stop words
review_cleaned = [words for words in review if words not in stopwords.words('english')]
# Stemming
if(not(Lemma)):
#stemming words so that we can get into the
root word stemmer = PorterStemmer()
review_cleaned = [stemmer.stem(words) for words in review_cleaned]
return ' '.join([words for words in review_cleaned])
#Lemmatizing
else:
Lemmatizer = WordNetLemmatizer()
review_cleaned = [Lemmatizer.lemmatize(words) for words in review_cleaned] rev = ' '.join([words for words in review_cleaned])
return rev The above function processes each of the raw positive raw reviews it the data and return the cleaned review.we have set Lemma = 1so that i could easily switch using the same function
Lemma = 1 Now lets gets the things done!!
data['cleaned_reviews'] = data['Phrase'].apply(lambda x : clean_reviews(x)) data['cleaned_reviews'] 0 series escapade demonstrating adage good goose... 1 series escapade demonstrating adage good goose 2 series 3 4 series 5 escapade demonstrating adage good goose 6 7 escapade demonstrating adage good goose 8 escapade 9 demonstrating adage good goose 10 demonstrating adage 11 demonstrating 12 adage 13 14 adage 15 good goose 16 17 good goose 18 19 good goose 20 21 good goose 22 good 23 goose 24 25 goose 26 goose 27 also good gander occasionally amuses none amou... 28 also good gander occasionally amuses none amou... 29 upto no of positive reviews
Now we have seen how will be dealing with raw reviews,Lets apply it to the whole sentiments data.
Sentiment Analysis and Predictive Modeling
Now lets clean all the reviews by applying the clean_reviews to all sentiments and create a new column in the dataframe 'cleaned_reviews'
data['cleaned_reviews'] = data['Phrase'].apply(lambda x : clean_reviews(x))
data['cleaned_reviews'] It takes some 3-5 minutes to process as it has 1,50,000 reviews.Now we will be using our cleaned reviews as feature and start building our predictive model using various NLP techniques
NLP Methods for Text Analysis
In Natural Language Processing there are several techniques or methods to analyze text data.some of the famous algorithms areBag of Words,TfIdf(Term Frequency Inverse Document Frequency) and Word2vec.We
will be using Bag of Words and Tfidf for Feature Extraction.Lets see both of the algorithms.
Bag of Words
The bag-of-words model is a way of representing text data when modeling text with machine learning algorithms. The bag-of-words model is simple to understand and implement and has seen great success in problems such as language modeling and document classification.
TFIDF
TFIDF(Term frequency inverse document frequency) is also one of the techniques for dealing with text data.In Bag of Words model,we simply count the occurrence of words and simply write the count at a particular index in the feature vector . But since we are only using count , words which are rare in the reviews will have less impact on predicting the sentiment . TFIDF measures the number of times that words appear in a given document(Term Frequency).The Idf term is the total occurrence of a word in all documents to total no of documents in the dataset.

Now we will be building a sklearn pipeline to use both the Bag of Words and Tfidf to calculate feature vectors
Building a Sentiment Classifier
from sklearn.pipleline import pipeline
from sklearn.feature_extraction import Tfidf,CountVectorizer TfIdf and CountVectorizer are the sklearn implementation of Tfidf and Bag of Words implementation of sklearn.
BOW = CountVectorizer(max_features=5000)
BOW_Features = BOW.fit_transform((data['cleaned_reviews']))
BOW_Features <156060x5000 sparse matrix of type ''with 524767 stored elements in Compressed Sparse Row format>
We have got a sparse matrix of 156000x5000 where each row corresponds to a single document and a feature vector of 5000 features. CountVectorizer allows us choose an arbitrary size of feature vector
Now we will fit a TfIdf vectorizer on the bag of words feature
tfidf = Tfidf()
tfidf_features = tfidf.fit_transform(max_features = 5000)
tfidf_features <156060x2000 sparse matrix of type ''with 419006 stored elements in Compressed Sparse Row format>
Now we will train a naive Bayes classifier for sentiment analysis.Naive Bayes is very popular for text classification and is used popularly.
Train Test Split
We will split our whole tfidf sparse matrix into train and test using sklearn's train_test_split
from sklearn.cross_validation
import train_test_split X_train, X_test, y_train, y_test = train_test_split(tfidf_features, data['Sentiment'], test_size=0.33, random_state=42) Lets train our model on Multinomial Naive Bayes which is used for Multi classification Problem.
from sklearn.naive_bayes import MultinomialNB()
model_naive = MultinomialNB()
model_naive.fit(X_train,y_train) Now lets predict the values in the test set and see its accuracy
predictions = model_naive.predict(X_test)
accuracy(y_test,predictions) 0.562
Its seems like we have achieved a good accuracy better than random guessing.Naive Bayes is not performing that well in sentiment analysis.
Random Forest Classifier
As we have seen naive Bayes is not giving better predictions,Lets use random forest an ensemble of Decision Trees.
from sklearn.ensemble
import RandomForestClassifier
model_randomf = RandomForestClassifier(n_estimators=100)
model_randomf.fit(X_train,y_train) Lets check the predictions and accuracy of our random forest model.
predictions = model_randomf.predict(X_test)
print "accuracy :",accuracy_score(y_test,predictions) accuracy : 0.6189708737864078
Whoo ! a 5% increment in accuracy using random forest.we have improved our model performance significantly using random forest.